
6 minutes read
GPT‑5: my API quick start guide
 Written by
Written byTable of contents
Introduction to GPT-5
OpenAI introduced GPT-5 on August 7, 2025. It is built for deeper reasoning, better code help, and agent-style workflows. It also adds two controls that matter in real apps: verbosity and reasoning_effort. In the API, GPT-5 supports up to 272,000 input tokens plus up to 128,000 tokens for reasoning and output, for 400,000 tokens total. For an overview of what is new for developers, see the official post on GPT-5 for developers.
If you are new to large language models, skim my plain-English explainer on how GPT-style LLMs work. You will prompt better after.
Ready? Let’s ship your first GPT-5 request.
Create an account to get your GPT-5 API key
- Create an account or sign in.
- Confirm your email address.
- Log in.
- Open the Billing overview page and add credit or a payment method so your keys work right away (see prepaid billing).
- Generate your first API key for GPT-5. Keys are shown once, paste it into a password manager right away.
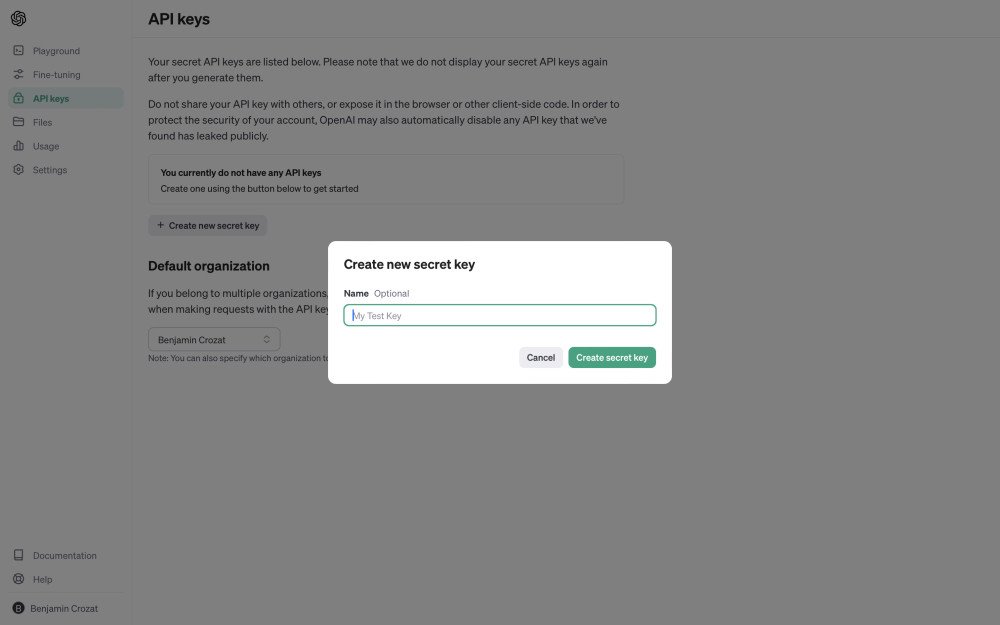
Got your key? Great. Time to hit the API.
How to make your first request to GPT-5
OpenAI’s Responses API is the modern endpoint. The Chat Completions API still works, but start with Responses when you can. See the Responses API overview for details.
macOS and Linux (Responses API):
curl -s https://api.openai.com/v1/responses \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-5",
"input": [
{ "role": "user", "content": [{ "type": "input_text", "text": "Hello!" }] }
],
"verbosity": "medium",
"reasoning_effort": "minimal",
"max_output_tokens": 200
}'
Windows (one-liner, Chat Completions still fine):
curl -X POST -H "Content-Type: application/json" -H "Authorization: Bearer %OPENAI_API_KEY%" https://api.openai.com/v1/chat/completions -d "{ \"model\": \"gpt-5\", \"messages\": [{\"role\":\"user\",\"content\":\"Hello!\"}], \"verbosity\":\"medium\", \"reasoning_effort\":\"minimal\", \"max_completion_tokens\":200 }"
Pro tip: use “gpt-5” to track the latest GPT-5 snapshot. If you need strict reproducibility, pin a dated snapshot like “gpt-5-2025-08-07”.
Token budget: the API supports up to 272,000 input tokens plus up to 128,000 output tokens, for 400,000 tokens total. Your usage tier must be high enough to handle long prompts and high TPM. Check your org’s limits here: usage tiers and rate limits.
Endpoint notes right where they matter:
- Responses API uses max_output_tokens and text.format for JSON.
- Chat Completions API uses max_completion_tokens (or max_tokens for legacy) and response_format. Mixing these fields will cause an error.
Structured outputs with the Responses API
In the Responses API, JSON control lives under text.format. Here is a minimal shape:
curl -s https://api.openai.com/v1/responses \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-5",
"input": [
{ "role": "system", "content": [{ "type": "input_text", "text": "Return compact JSON only." }] },
{ "role": "user", "content": [{ "type": "input_text", "text": "Solve 8x + 31 = 2." }] }
],
"text": {
"format": {
"type": "json_schema",
"name": "equation_solution",
"schema": {
"type": "object",
"properties": {
"steps": { "type": "array", "items": { "type": "string" } },
"final_answer": { "type": "string" }
},
"required": ["steps", "final_answer"],
"additionalProperties": false
},
"strict": true
}
}
}'
For the Chat Completions API, keep using response_format (json_schema or json_object). Do not send text.format to Chat Completions, or the call will fail. If you want a deeper dive, see the Cookbook guide on structured outputs with JSON Schema.
Vision and multimodal (quick start)
GPT-5 accepts text and images in one request. With the Responses API, add image parts as { "type": "input_image", "image_url": "<url or data URL>", "detail": "auto" }, then put your text after the image for better results.
Supported image formats: PNG, JPEG/JPG, and non-animated GIF (see image input guidance).
Image URL example:
curl -s https://api.openai.com/v1/responses \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-5",
"input": [
{
"role": "user",
"content": [
{ "type": "input_image", "image_url": "https://cdn.example.com/slide.jpg", "detail": "auto" },
{ "type": "input_text", "text": "Describe this slide in 5 bullets." }
]
}
],
"max_output_tokens": 250
}'
Base64 option:
{ "type": "input_image", "image_url": "data:image/jpeg;base64,...." }
Pro tips
- One image per content part unless you are explicitly comparing. Caption each if you include many.
- Prefer URLs when you reuse the same image, especially in long threads. Base64 increases payload size and slows requests.
- Always cap max_output_tokens so multimodal answers stay on budget.
Verbosity (new)
What it does: controls how compact or expansive the answer is without changing your prompt. Values: “low”, “medium” (default), “high”.
When to use low: terse assistants, tool-first UX, status updates. When to use high: audits, code reviews, teaching.
"verbosity": "low"
Caveat: verbosity is a hint. The hard cap is still your token limit (max_output_tokens or max_completion_tokens). See the guide on controlling the length of responses.
Reasoning effort (new)
What it does: sets how much internal reasoning the model does before responding. Values: “minimal”, “low”, “medium” (default), “high”. “minimal” is new and fast for simple tasks.
- Use “minimal” for retrieval, formatting, simple transforms, and low-latency UX.
- Use “high” for complex planning, multi-step refactors, and tradeoff-heavy tasks.
"reasoning_effort": "minimal"
GPT-5 pricing
| Model | Input (per 1M tokens) | Output (per 1M tokens) |
|---|---|---|
| gpt-5 (400K context) | $1.25 | $10.00 |
| gpt-5-mini (400K context) | $0.25 | $2.00 |
| gpt-5-nano (400K context) | $0.05 | $0.40 |
| gpt-4.1 (1M context) | $2.00 | $8.00 |
| gpt-4.1-mini (1M context) | $0.40 | $1.60 |
| gpt-4.1-nano (1M context) | $0.10 | $0.40 |
Prompt-cached input is cheaper. Check the official pages for current numbers: models and pricing and the developer notes in GPT-5 for developers.
Output limits: GPT-5 can emit up to 128K tokens per call. GPT-4.1 supports a 1M-token context and has an output cap of about 32K. See the 4.1 post for details: GPT-4.1.
GPT-5 (full), mini, or nano?
- GPT-5 (full): best quality for deep reasoning, complex coding, and long-context analysis.
- GPT-5 mini: good when you need lower cost and crisp prompts.
- GPT-5 nano: best for very low latency and heavy volume.
There is also gpt-5-chat-latest if you want a non-reasoning chat flavor.
Conclusion
Pick GPT-5 when you want the highest quality and long context. Use mini when cost matters and answers can be shorter. Use nano for the lowest latency. Remember the limits: 272,000 input tokens plus up to 128,000 output tokens, for 400,000 tokens total. Next steps: review models and pricing, skim GPT-5 for developers, and try the curl quickstarts above using the Responses API overview.
Did you like this article? Then, keep learning:
- How to build a ChatGPT plugin using Laravel, complementing GPT-5 API use
- Step-by-step guide to start using GPT-3.5 Turbo API for beginners
- Learn how to access and use GPT-4 Turbo's API effectively
- Understand how GPT-style AIs like GPT actually work
- Learn to use PHP with OpenAI's API and GPT for practical projects
0 comments