
6 minutes read
How to use GPT-3.5 Turbo's API, step by step
 Written by
Written byTable of contents
Introduction to GPT-3.5 Turbo
GPT-3.5 Turbo is a famous Artificial Intelligence Large Language Model made by OpenAI. Its capabilities powered the first version of ChatGPT.
GPT-3.5 Turbo can generate text outputs known as “completions” that can be used to build a range of applications like truly personal assistants, smart chatbots, grammar checkers, spam filters, code generators, and more! The list could go on forever.
If you are unfamiliar with LLMs, take some time to get up to speed thanks to my simple-to-understand article about how LLMs such as GPT work.
Now, let’s dive into this step-by-step tutorial that will help you make your first requests to GPT-3.5 Turbo!
If you are a paid OpenAI API user, you can enjoy GPT-4 Turbo now and I also wrote a tutorial about it: Start using GPT-4 Turbo’s API in 5 minutes.
Create an account to get your GPT-3.5 Turbo API key
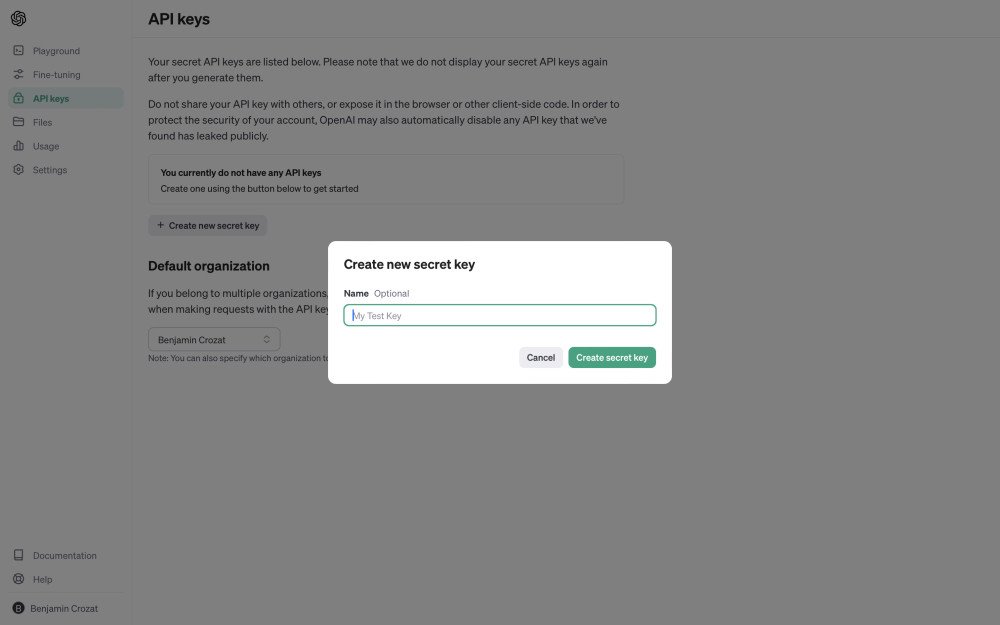
- Generate your first API key. Be careful, it will only be displayed once. Copy and paste it into a password manager so it’s stored securely.
- Start using GPT-3.5 Turbo’s API! (Continue reading to learn how.)
Make your first request to GPT-3.5 Turbo
Requesting GPT-4 Turbo’s API is easy peazy and we’ll do it with curl this time. Obviously, the API can be requested thanks to the HTTP layer of your favorite programming language.
Here’s the process broken down into four very clear steps:
-
Locate your API key: You should have generated this already if you followed the previous section. It usually looks like a long string of random numbers and letters. Make sure to keep it secure.
-
Open your terminal: If you want to start experimenting with curl, open your terminal.
-
Input the curl command: Curl is a command-line tool used to transfer data. For the chat API, you could use a command like this:
curl -X POST \
-H "Content-Type: application/json" \
-H "Authorization: Bearer YOUR_API_KEY" \
https://api.openai.com/v1/chat/completions -d \
'{
"model": "gpt-3.5-turbo-1106",
"messages": [
{
"role": "system",
"content": "You are an assistant."
},
{
"role": "user",
"content": "Hello!"
}
]
}'
- Replace
YOUR_API_KEYwith your actual API key. - The string after
-dspecifies the request body in JSON format. It gives the model “gpt-3.5-turbo-1106” (GPT-3.5 Turbo) two messages: a system message that sets up the role of the assistant, and a user message.
- Run the command: After pressing enter, you should see a response from the API in your terminal window after a few seconds at most.
Remember, this is a basic example. You might want to adjust the request depending on your specific needs, such as including more messages in the conversation.
Learn more on the official API reference for Chat Completions.
Pro tip: One API call can accept up to 128,000 tokens with gpt-4-1106-preview. A token is a numerical representation of your text. All your messages as well as the output from the model cannot exceed this limit. And for those who don’t know, 1,000 tokens roughly equals 750 English words.

Enable the JSON mode with GPT-3.5 Turbo
You can now force GPT-3.5 Turbo (as well as GPT-3.5 Turbo) to output JSON consistently thanks to the new JSON mode.
(Most people here know what JSON is, but for the others, JSON is a way of storing information that both people and computers can understand. It uses text to organize data into lists and sets of “name: value” pairs.)
Before, asking GPT to output JSON was already possible. But you could randomly get text instead of the JSON you requested. The new JSON mode aims to stop that.
Using it is as simple as adding a new object, and setting a system message that instructs the model to reply with JSON (but keep reading, because there are a few gotchas):
curl -X POST \
-H "Content-Type: application/json" \
-H "Authorization: Bearer YOUR_API_KEY" \
https://api.openai.com/v1/chat/completions -d \
'{
"model": "gpt-3.5-turbo-1106",
"messages": [
{
"role": "system",
- "content": "You are an assistant."
+ "content": "You are an assistant, and you only reply with JSON."
},
{
"role": "user",
"content": "Hello!"
}
- ]
+ ],
+ "response_format": {
+ "type": "json_object"
+ }
}'
- As you can see, we added the following object:
"response_format": { "type": "json_object" }
- We set the system message to “You are an assistant, and you only reply with JSON.”, but it can be anything you want as long as “JSON” is mentioned. If you don’t do that, the API call will fail and throw the error “‘messages’ must contain the word ‘json’ in some form, to use ‘responseformat’ of type ‘jsonobject’.“
{ "role": "system", "content": "You are an assistant, and you only reply with JSON." }
- But be careful! While the model will now always output JSON, you will never be able to get 100% accuracy in its structure.

GPT-3.5 Turbo’s pricing (it’s cheaper than ever!)
Pricing can change, so please double check. That being said, at the time I’m writing these lines, GPT-3.5 Turbo’s pricing is $0.0010 per 1,000 tokens for the input and $0.0020 per 1,000 tokens for the output.
This is such good news for developers who want to build their dream tools for cheaper thanks to the best-known language model. I know I already have something planned. What about you?
Ideas to build thanks to GPT-3.5 Turbo’s API
Artificial Intelligence enables developers to build products we couldn’t hope to before. For instance, I created Nobinge, a tool that lets you summarize and chat with YouTube videos.
Here are a bunch of ideas to experiment with:
- Additional AI-based features for existing products
- Automated email responses
- Chatbots
- Content summarizers
- Personal assistants
- Personalized teaching programs
- Sentiment analysis tools
- Spam filters
You can even add voices to your projects thanks to another endpoint!
Did you like this article? Then, keep learning:
- Learn how to build a ChatGPT plugin with Laravel, complementing API usage
- Discover how to generate Laravel Factories quickly using ChatGPT AI
- Explore newer GPT-4 Turbo API similar to GPT-3.5 Turbo with added features
- Learn about a smaller, cost-effective GPT-4o mini API option
- Understand the GPT-4o API, a relevant successor for GPT-3.5 Turbo users
- Get a deeper understanding of how GPT and other language AIs work internally
- See how PHP can be used to easily leverage OpenAI's GPT APIs in your projects
- Add realistic voice features using OpenAI's Text-to-Speech API
0 comments