

4 minutes read
Access and use GPT‑4.1 nano's API. 5 minutes, tops.
 Written by
Written byTable of contents
Introduction to GPT‑4.1 nano
GPT‑4.1 nano is OpenAI’s speed demon. It keeps the full one‑million‑token context window that the larger 4.1 models enjoy, yet it delivers responses in a blink and at one of the lowest prices on the market. The model is ideal for high‑volume classification, autocomplete, and any other job where latency matters more than absolute brainpower.
If large language models are still mysterious, take five minutes to read my entry‑level explanation of how GPT‑style LLMs work then come back here.
Create an account to get your GPT‑4.1 nano API key
- Create or sign in to your account at OpenAI.
- Confirm your email address.
- Log in to the developer dashboard.
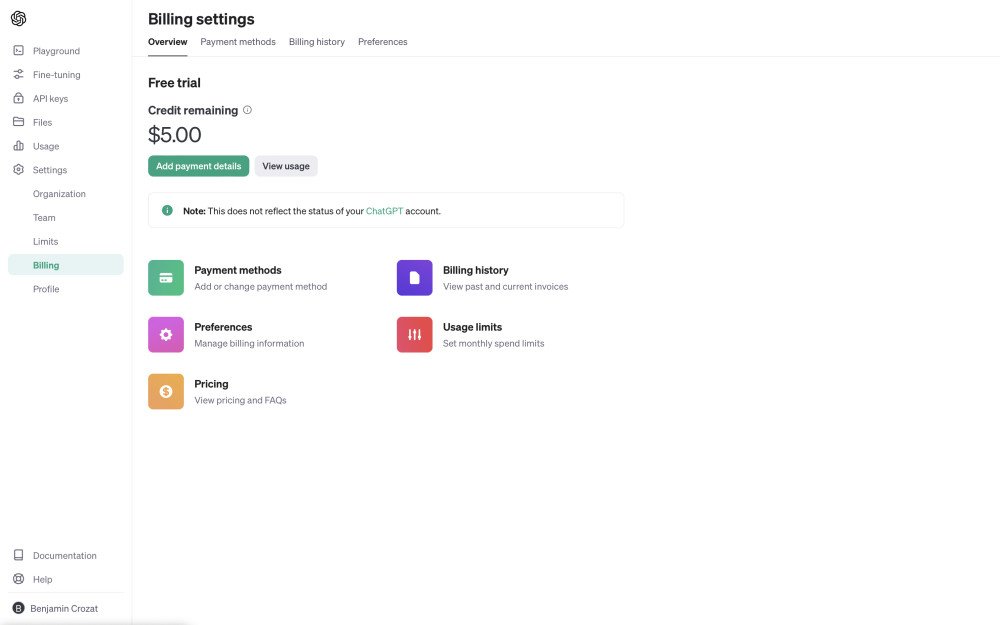
- Visit the Billing overview page and add credit or a payment method. New accounts do not receive promo credit anymore.
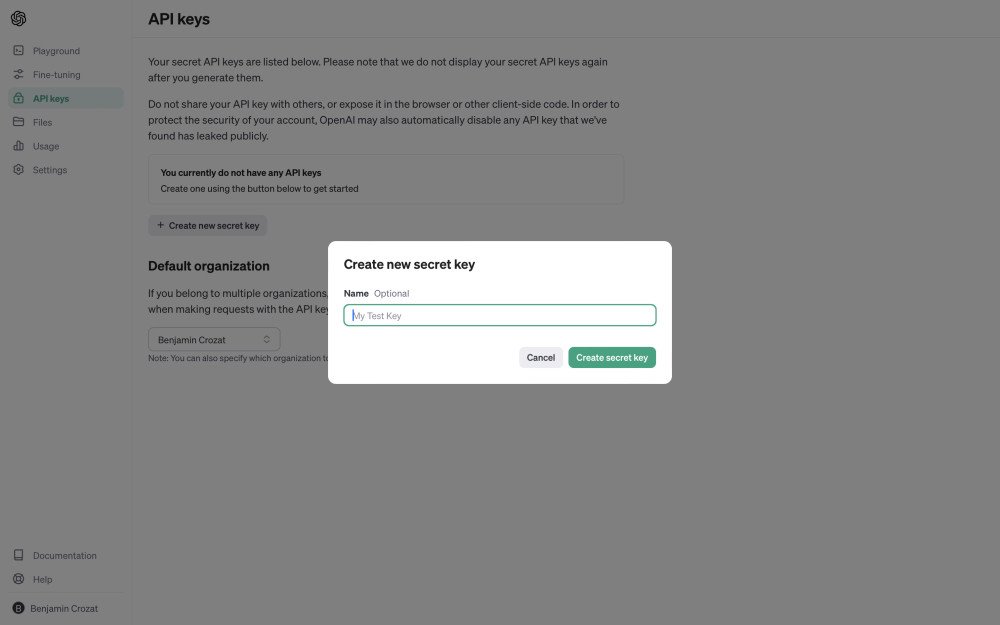
- Generate an API key at api‑keys. The key appears once; store it securely in your password vault.
How to make your first request to GPT‑4.1 nano
Open a terminal and run the snippet that follows. Swap $OPENAI_API_KEY with your actual key.
macOS or Linux:
curl -X POST \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
https://api.openai.com/v1/chat/completions -d '{
"model": "gpt-4.1-nano",
"messages": [
{ "role": "system", "content": "You are an assistant." },
{ "role": "user", "content": "Hello!" }
]
}'
Windows command prompt (one‑liner):
curl -X POST -H "Content-Type: application/json" -H "Authorization: Bearer %OPENAI_API_KEY%" https://api.openai.com/v1/chat/completions -d "{ \"model\": \"gpt-4.1-nano\", \"messages\": [{\"role\":\"user\",\"content\":\"Hello!\"}] }"
Tip: The alias gpt‑4.1‑nano tracks the latest nano weights automatically.
One request can include up to 1,000,000 tokens, which equals about 750,000 English words.
Enforce JSON output with GPT‑4.1 nano
JSON mode is identical across the 4.1 family. Supply a response_format block containing a concise JSON schema and the model will stay in‑bounds.
curl -X POST \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
https://api.openai.com/v1/chat/completions -d '{
"model": "gpt-4.1-nano",
"messages": [
{ "role": "system", "content": "Return answers in strict JSON." },
{ "role": "user", "content": "Solve 8x + 31 = 2." }
],
"response_format": {
"type": "json_schema",
"json_schema": {
"strict": true,
"schema": {
"type": "object",
"properties": {
"steps": { "type": "array", "items": { "type": "string" } },
"final_answer": { "type": "string" }
},
"required": ["steps", "final_answer"],
"additionalProperties": false
}
}
}
}'
Every character inside the schema counts toward your token budget, so keep things compact.
GPT‑4.1 nano pricing
| Model | Input (per 1 M) | Output (per 1 M) |
|---|---|---|
| gpt‑4.1 nano | $0.10 | $0.40 |
| Cached input | $0.025 | — |
Cached calls enjoy a 75 percent discount. The figure above reflects that.
Ten ideas that suit GPT‑4.1 nano
- Real‑time chat profanity filters: Classify messages on the fly without slowing chat throughput.
- Autocomplete in code editors: Return next‑token predictions with sub‑100‑ms latency.
- Spam triage for help desks: Tag incoming tickets instantly so human agents focus where it counts.
- Thumbnail alt‑text generators: Process thousands of product images per minute for accessibility compliance.
- IoT sensor anomaly detection: Stream sensor readings and flag odd patterns as they occur.
- Voice command quick parsers: Convert spoken requests to structured JSON in smart‑home hubs.
- Large scale survey classifiers: Group open‑ended answers from millions of respondents in real time.
- Portfolio stock alerting: Watch price feeds and push alerts only when criteria hit, avoiding heavy compute.
- Lightweight document redactors: Scrub personal data from PDFs inside pipelines that are cost‑sensitive.
- Gaming NPC chatter: Generate short in‑game lines without eating your frame budget.
Need natural‑sounding speech? OpenAI’s TTS endpoint pairs nicely. Read my how‑to.
Did you like this article? Then, keep learning:
- Step-by-step guide for GPT-3.5 Turbo API usage offers broader context
- Detailed guide to using GPT-4 Turbo API complements nano's API usage
- Learn to use GPT-4o mini's API for a more affordable option
- Guide to using GPT-4o's API provides another perspective on GPT-4 models
- Understand how language-based AIs like GPT work to deepen foundational knowledge
- Guide to GPT-4.1 API overall for a broader understanding beyond nano
- Introductory guide for GPT-4.1 mini API usage complements nano's API
0 comments