
7 minutes read
Access and use GPT‑4.1's API. 5 minutes, tops.
 Written by
Written byTable of contents
- → Introduction to GPT‑4.1
- → Create an account to get your GPT‑4.1 API key
- → How to make your first request to GPT‑4.1
- → How to enable JSON mode with GPT‑4.1
- → About the 1 million tokens context window
- → Vision and multimodal (quick-start)
- → GPT‑4.1 pricing
- → GPT-4.1 full, mini, or nano?
- → 10 project ideas unlocked by GPT‑4.1
Introduction to GPT‑4.1
GPT‑4.1 is OpenAI’s brand‑new flagship model for 2025. It speaks text and images, handles a mind‑blowing 1,000,000‑token window per request, and still answers faster than GPT‑4o. Even better, it costs less. (See pricing below.)
If you are new to large language models, take a moment to skim my plain‑English explainer on how GPT‑style LLMs work. It will save you headaches later.
Ready to roll? Let’s build your first GPT‑4.1 request.
Create an account to get your GPT‑4.1 API key
- Create an account or sign in.
- Confirm your email address.
- Log in.
- Open the Billing overview page and add credit or a payment method so your keys work right away. (The free‑credit program ended mid‑2024.)
- Generate your first API key for GPT‑4.1. Keys are shown once; paste it into a password manager immediately.
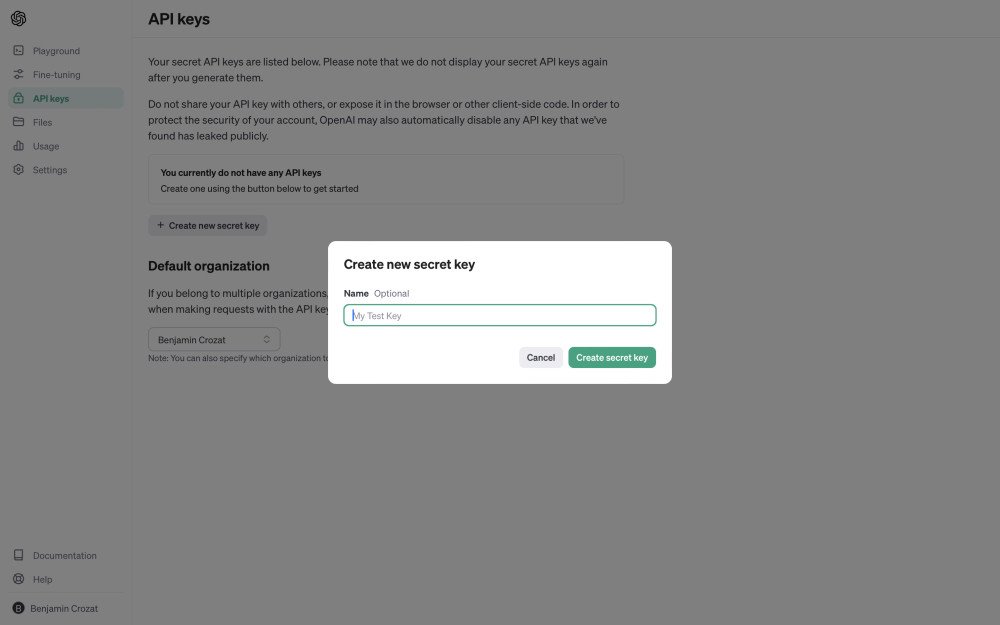
Got your key? Great. Time to hit the API.
How to make your first request to GPT‑4.1
Open your terminal and run this cURL snippet:
macOS and Linux:
bash
curl -X POST
-H “Content-Type: application/json”
-H “Authorization: Bearer $OPENAI_API_KEY”
https://api.openai.com/v1/chat/completions -d ‘{
“model”: “gpt-4.1”,
“messages”: [
{ “role”: “system”, “content”: “You are an assistant.” },
{ “role”: “user”, “content”: “Hello!” }
]
}’
Windows command prompt (one‑liner):
cmd curl -X POST -H “Content-Type: application/json” -H “Authorization: Bearer %OPENAI_API_KEY%” https://api.openai.com/v1/chat/completions -d “{ "model": "gpt‑4.1", "messages": [{"role":"user","content":"Hello!"}] }”
Pro tip: The alias gpt‑4.1 always points at the newest 4.1 weights, so you enjoy silent upgrades.
Token budget: a single call can swallow up to 1,000,000 tokens (roughly 750,000 English words).
How to enable JSON mode with GPT‑4.1
GPT‑4.1 obeys JSON schemas the same way GPT‑4o did. Add a response_format field and you get rock‑solid JSON every time.
bash
curl -X POST
-H “Content-Type: application/json”
-H “Authorization: Bearer $OPENAI_API_KEY”
https://api.openai.com/v1/chat/completions -d ‘{
“model”: “gpt-4.1”,
“messages”: [
{ “role”: “system”, “content”: “Serve answers as tight JSON.” },
{ “role”: “user”, “content”: “Solve 8x + 31 = 2.” }
],
“response_format”: {
“type”: “json_schema”,
“json_schema”: {
“strict”: true,
“schema”: {
“type”: “object”,
“properties”: {
“steps”: { “type”: “array”, “items”: { “type”: “string” } },
“final_answer”: { “type”: “string” }
},
“required”: [“steps”, “final_answer”],
“additionalProperties”: false
}
}
}
}’
Keep schemas lean; every character counts against your million‑token window.
About the 1 million tokens context window
The 1 million limit is real but your rate‑limit tier must be high enough to feed that many tokens per minute. Many tier‑1 organizations report hitting HTTP 429 around 30K tokens per minute. Double‑check your org’s actual quota before chunking a megaprompt.
FYI, hitting higher tiers requires some amount of spendings.
Vision and multimodal (quick-start)
Nowadays, Large Language Models are also trained on other things than just text. That’s what we call multimodality. For instance, GPT is trained on images, which allows it to have vision capabilities.
GPT-4.1 supports these formats and sizes:
- Formats: JPEG, PNG, WEBP, and HEIC.
- Limits: ≤ 20 MB per image and ≤ 20 images per request.
My recommendation: keep images ~1-2 MP. Larger adds latency with little gain.
Then, how do you attach images to your message to GPT? Here are two ways:
- Encode it to base64. This is best for prototyping or working offline.
- Pass an URL. This is the best, fastest, and my favorite way.
Send images to GPT-4.1
Your first option, and the best, if to send an URL:
bash
curl https://api.openai.com/v1/chat/completions
-H “Content-Type: application/json”
-H “Authorization: Bearer $OPENAI_API_KEY”
-d ‘{
“model”: “gpt-4.1”,
“messages”: [
{
“role”: “user”,
“content”: [
{ “type”: “image_url”, “image_url”: { “url”: “https://cdn.example.com/slide.jpg” } },
{ “type”: “text”, “text”: “Describe this slide.” }
]
}
]
}’
The second option is to swap the url value above for a data URL:
json “image_url”: { “url”: “data:image/jpeg;base64,$(base64 -w0 slide.jpg)” }
Pro tips
- One image per message keeps the model focused; for a gallery, add a short caption to each image part.
- Put your text prompt after the image in the same message for better results.
- For long conversations, URLs are lighter than repeatedly sending Base64.
All GPT-4.1 variants inherit GPT-4o’s vision weights, so image-in / text-out works the same. No extra model switch required.
GPT‑4.1 pricing
Newer models doesn’t necessarily mean pricer. GPT-4.1 is extremely affordable!
| Model | Input (per 1 M) | Output (per 1 M) |
|---|---|---|
| gpt‑4.1 (1 M context) | $2.00 | $8.00 |
| gpt‑4.1‑mini (1 M context) | $0.40 | $1.60 |
| gpt‑4.1‑nano (1 M context) | $0.10 | $0.40 |
| gpt-4o (128 K context) | $5.00 | $15.00 |
| gpt-4o-mini (128 K context) | $0.60 | $1.80 |
As you can see, GPT-4.1 costs less than GPT-4o despite the bigger context window. This is incredible when you think that not so long ago, the original GPT-4’s cost was through the roof and its context window was 32K for some lucky developers, and 8K for the rest of us!
It even has smaller version that are even cheaper. But what are the trade-offs? Let’s see about that in the next section.
GPT-4.1 full, mini, or nano?
As you saw in the pricing table, GPT-4.1 is available in three flavors: full, mini, and nano. Each are designed for different needs. They all share the 1 million-token context window, but differ significantly in speed, cost, and use-case sweet spots. Here’s how you pick yours:
-
GPT-4.1 (full): This is the flagship. It’s powerful, versatile, and handles deep reasoning tasks, massive documents, complex coding, and sophisticated multimodal prompts. When you need uncompromising quality, choose GPT-4.1.
-
GPT-4.1 mini: Around twice as fast as the flagship and about 83% cheaper, mini hits the sweet spot for real-time applications, live chats, support bots, or any scenario where you want fast responses without draining your budget.
-
GPT-4.1 nano: The smallest sibling but also the quickest and cheapest. Nano is ideal for simple classification tasks, auto-completion features, mobile apps, or anything that runs at scale. At about 95% cheaper than full GPT-4.1, nano makes deploying large-scale AI affordable for everyone.
10 project ideas unlocked by GPT‑4.1
… and generated by GPT-4.1!
- Whole‑repo refactorers: Feed the model your monolith and an upgrade brief; get back pull requests instead of single‑file rewrites.
- Legal discovery copilots: Drop in gigabytes of PDFs and ask clarifying questions.
- Enterprise memory chatbots: Keep every support ticket ever written in the prompt and never ask customers to repeat themselves.
- Code compliance auditors: Scan enormous codebases for OWASP issues without paging in files one by one.
- Million‑token storyboards: Hand GPT‑4.1 a screenplay and all storyboard sketches; receive continuity‑checked shot lists.
- Financial data wranglers: Parse multi‑sheet Excel workbooks, cross‑match with SEC filings, and spit out red‑flag reports.
- Video essay assistants: Upload lecture videos with transcripts, then query them live during study sessions.
- Long‑term personal journals: Store years of journaling data and let the model surface patterns and throwbacks.
- Multi‑doc contract generators: Provide prior agreements and a term sheet; receive a draft contract that references legacy clauses correctly.
- Mega‑scale RAG pipelines: Chunk millions of tokens from your company wiki and ask real‑time questions without an external vector DB.
So, which one will you build? Please share it in the comments below!
Did you like this article? Then, keep learning:
- Step-by-step guide to start using GPT-3.5 Turbo API
- Step-by-step guide for accessing GPT-4 Turbo's API
- Step-by-step guide for using the GPT-4o mini API cost-effectively
- Step-by-step guide to access and use GPT-4o's API
- Simplified explanation of how GPT and language AIs work
- Learn to leverage PHP to work with OpenAI's API and GPT easily
- Latest info on GPT-5 API, successor to GPT-4.1
0 comments